
Introduction
I spend a lot of time interacting with developers on Neon’s Discord Server—if you’re not already a member, you should join us! One recurring issue that I’ve seen developers ask for assistance with is identifying a reason for suboptimal response times from their application’s API endpoints.
Various factors come into play when accounting for an API endpoint’s overall response time. The graphic below provides a simplified representation of the lifecycle of a request to an API endpoint. It illustrates that the user’s network latency, backend logic, and the network latency between the backend and database (database latency) all factor into the overall response time.
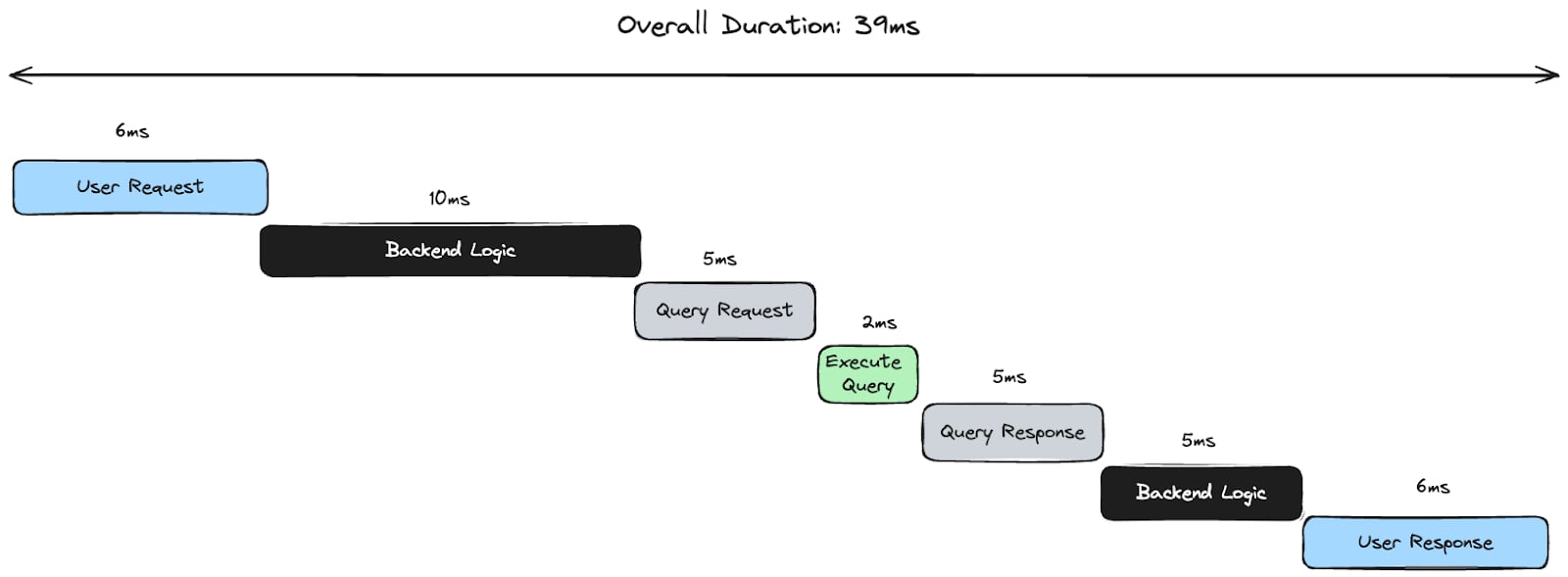
In this article, I’ll explore the impact that database latency has on response times since that has been a key topic of discussion with developers on Discord.
We built Neon’s Regional Latency Dashboard to establish a baseline latency expectation between popular hosting providers and Neon. Keep reading to learn more about it and how to minimize the effects of latency on your application by optimizing your code, queries, and database connection management.
Measuring Latency to Neon’s Postgres
Measuring database latency is an essential step in understanding the response times you can achieve from API endpoints that interact with your database. Performing this measurement might seem trivial, but there are a few variables to bear in mind:
- Does your database receive consistent queries, thereby eliminating the impact of Neon’s cold starts? Or have you disabled Neon’s auto-suspend?
- If you’re using a serverless deployment platform, are your functions receiving consistent traffic and are warmed up as a result?
- Have you applied indexes and optimized your database queries?
For most production applications, the answer to these questions is yes, so it doesn’t make sense to include those overheads in measurements. We simply want to determine how long it takes for a production backend application to receive a response to a database query with a submillisecond execution time.
With this in mind, we built the Regional Latency Dashboard. It tracks latency numbers between various hosting providers and Neon regions. The recorded latencies are presented as a set of percentiles that you can use to gauge the best and worst-case latency scenarios between your backend hosting provider and Neon.
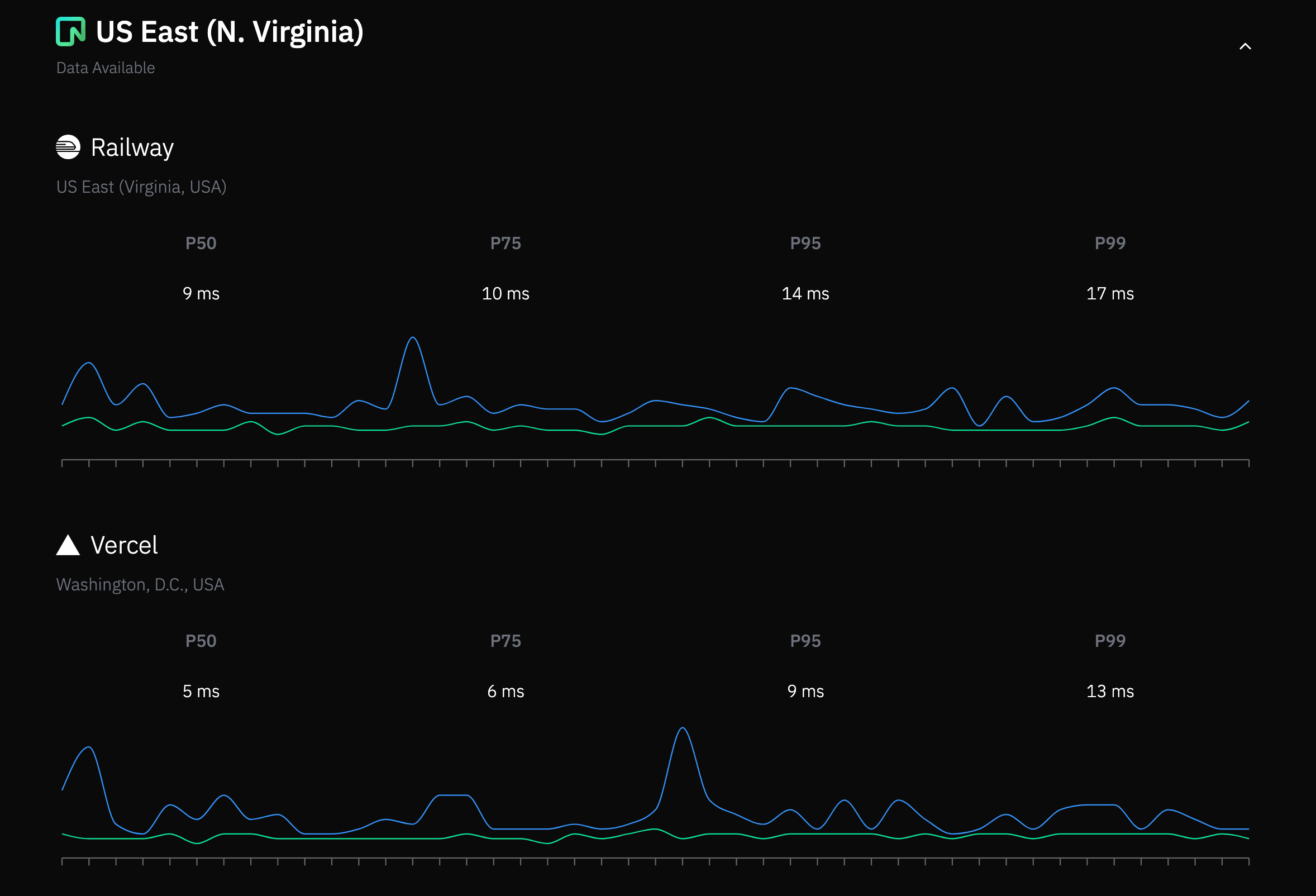
The code is open-source and hosted in the regional-latency repository on GitHub. One important thing to note is that we used our serverless driver’s HTTP mode to connect to the database. This keeps the benchmark fair when comparing serverless environments – where persistent connections cannot be used across invocations – versus traditional long-running servers.
Why It’s Critical to Minimise Latency
After looking at the numbers on our Regional Latency Dashboard, it’s clear that the closer your application is to your database, the better. Keeping your backend close to the database should provide API response times that are sufficiently snappy for well-optimized queries.
However, you might run into trouble if you need to issue multiple queries in sequential order. For example, I recently helped a developer who was having an API response time issue due to the effects of round-trip latency when issuing multiple queries. Here’s a quote (edited for clarity) that describes their issue:
One of our API endpoints performs over 200 database queries. The data was stored in a local SQLite database during initial development, and the cumulative time to perform those queries was ~500ms. Now that we’re hosting the data in Neon, it’s taking ~4 seconds.
There are scenarios where performing this many queries might be necessary, but it’s often a sign of the N+1 Problem, alongside some other issues we’ll discuss in subsequent sections.
A typical example of the N+1 Problem is a piece of code that fetches a list of records and then performs a subsequent query for each record returned from the original query.
// Perform an initial query to fetch a list of items
const orders = await db.query('SELECT customer_id, product_id FROM orders')
const customers = []
// For each item, perform a subsequent query
for (let i = 0; i < orders.length; i++) {
const id = orders[i].customer_id
const customer = await db.query(`SELECT * FROM customers WHERE id = ${id}`)
customers.push(customer)
}The greater the latency between your backend and database, the worse the compounding impact of N+1 queries becomes. For example, the illustration below shows an N+1 query that adds 96 milliseconds (12ms times 8) to an API endpoint’s response time.
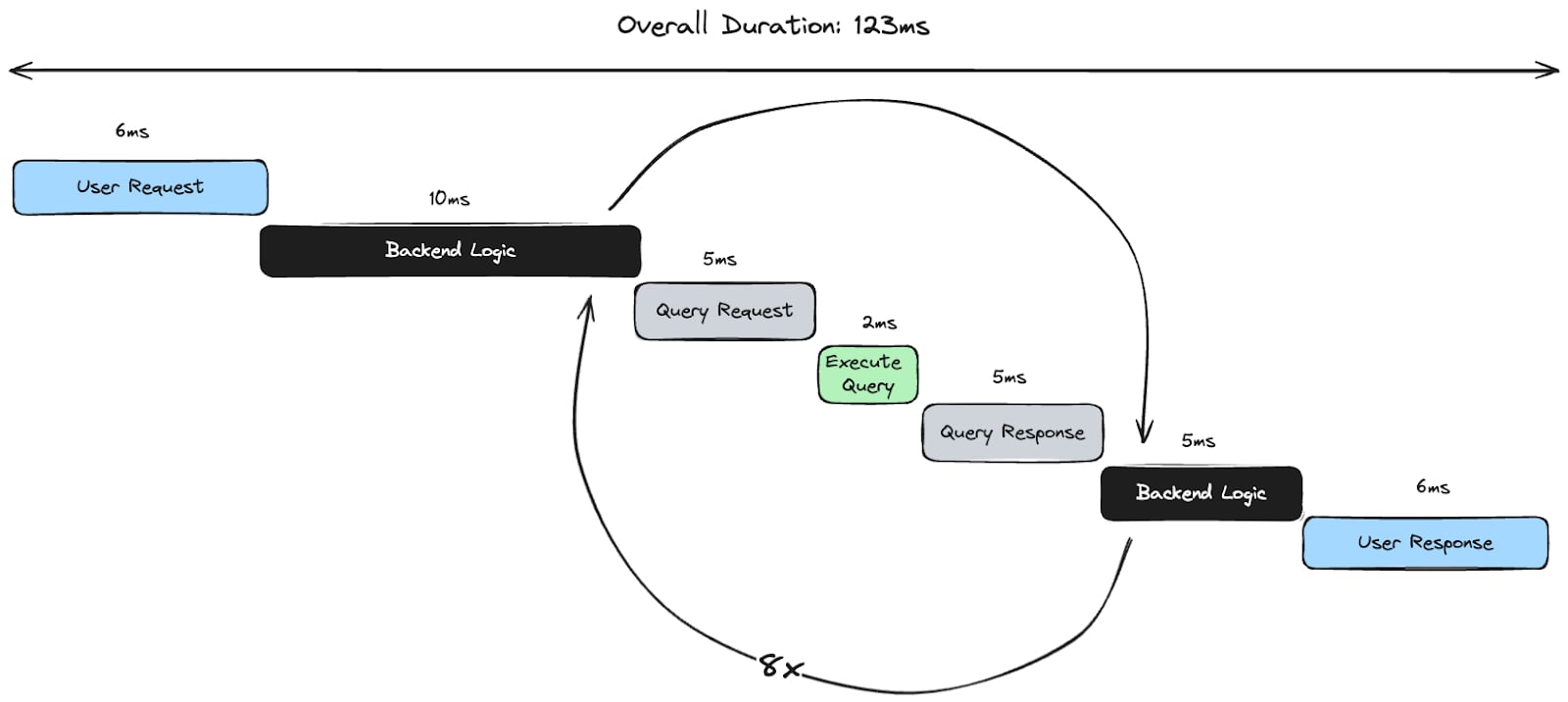
Using the numbers presented on the Regional Latency Dashboard, you can roughly estimate the best and worst-case scenarios for N+1 queries by multiplying against the P50 and P99 numbers, respectively.
Reducing the Impact of Latency
Naturally, reducing the number of round trips between your backend and database will reduce the compounding impact of latency. The following sections outline techniques for reducing database latency and solving the N+1 problem.
Solutions to N+1
Perhaps it’s obvious to some readers, but one solution to N+1 is to perform a single round-trip with a query that performs a JOIN. For example, performing a JOIN resolves the N+1 example shown in the previous code by returning the orders with the associated customer details in a single query.
const ordersWithDetails = await db.query(`
SELECT
o.customer_id,
o.product_id,
c.name,
c.email
FROM
orders o
INNER JOIN
customers c
ON
o.customer_id = c.customer_id;
`)
Alternatively, you can perform two queries; the first retrieves the orders, and the second retrieves the customer details. Yes, technically, this is multiple queries, but it’s bounded! This approach is useful if there are multiple orders for the same customer, and you don’t want to return redundant copies of customer data, as would be the case with the JOIN.
const customerIds = await db.query(
"SELECT customer_id FROM orders WHERE order_date = '2024-01-01'"
)
const ids = customerIds.map(row => row.customer_id).join(',')
const customerDetails = await db.query(
`SELECT id, name, email FROM customers WHERE customer_id IN (" ${ids} ");`
)The N+1 Problem and ORMs
What happens if you’re using an ORM and need to efficiently fetch an entity and its related entities from the database? Let’s look at an example using the Django framework for Python.
class Author(models.Model):
name = models.CharField(max_length=200)
email = models.EmailField()
def __str__(self):
return self.name
class Post(models.Model):
timestamp = models.DateField()
message = models.TextField()
author = models.ForeignKey(Author, on_delete=models.CASCADE)
def __str__(self):
return self.name
# Fetch posts and print the post content alongside the author
posts = Post.objects.order_by("timestamp")
for post in posts:
print(
post.message,
"by ",
post.author.name
)This code queries the database for post entities and then loops over each returned result, printing the name of the post’s author and the post content. Each invocation of the for loop sends an additional query to the database to get the author’s name, introducing the N+1 problem.
Thankfully, Django provides the prefetch_related() and select_related() functions to solve this problem. In our case, chaining the select_related("author") onto the order_by("timestamp") will resolve the problem by issuing a single query (and therefore a single round-trip) that performs the appropriate JOIN to fetch the posts and related author.
Other ORMs, such as Hibernate, have their own approach to N+1 – you’ll need to adapt your code according to your ORM’s documentation. Drizzle ORM provides SQL-like and relational interfaces where you can specify if a join should be performed to fetch all data in a single query.
Batching Queries
If you’re not using an ORM, you have explicit control over how you structure and issue queries. It’s quite easy to read and write code that issues queries sequentially.
import { neon } from '@neondatabase/serverelss'
const sql = neon(process.env.DATABASE_URL)
const data1 = await sql`SELECT * from table_a;`
const data2 = await sql`SELECT * from table_b;`This code would result in two roundtrips between your backend and Neon, adding a penalty to your endpoint’s response time, plus whatever time it takes for Postgres to process the queries. Batching the queries, as shown below, should cut the latency penalty incurred in the prior code sample roughly in half.
import { neon } from '@neondatabase/serverelss'
const sql = neon(process.env.DATABASE_URL)
const [data1, data2] = await sql.transaction([
sql`SELECT * from table_a;`,
sql`SELECT * from table_b;`,
]);Performing a simple benchmark that compares the sequential vs batched code demonstrated a 45% reduction in response time when using the batched queries.
Leverage Powerful Postgres Features
The RETURNING and ON CONFLICT clauses allow you to perform queries that might otherwise require multiple round trips in a single round trip.
For example, RETURNING can return the ID of a newly inserted row without issuing a follow-up SELECT query to obtain it.
INSERT INTO posts (author, message) VALUES (1, 'Hello, world!') RETURNING id;Drizzle ORM supports these clauses, so you can easily incorporate them into a JavaScript backend. For example, if an insert violates a unique constraint on an id field, you can update the existing record using ON CONFLICT (id) DO UPDATE instead of first performing a read to determine if an INSERT or UPDATE is required.
await db.insert(authors)
.values({ id: 1, name: 'Neon' })
.onConflictDoUpdate({ target: authors.id, set: { name: 'Neon' } });Reusing Connections
Reusing connections eliminates the overhead of establishing a new TLS connection between your backend and the Postgres database hosted on Neon for each incoming request – an operation that requires multiple round trips and is therefore impacted by latency between your backend and database.
The configuration required for reusing connections will depend on your runtime and application framework. In a previous blog post discussing Python and Django with Neon, we demonstrated how to enable connection reuse. Benchmarking our sample Django application showed an 8-9x reduction in API response times and a similar increase in application throughput when connection reuse was enabled.
Application-level Connection Pooling
This tip applies if you’re using a Postgres driver such as node-postgres or the WebSocket mode exposed by Neon’s serverless driver in Node.js. It can also be applied to other runtimes and drivers.
When a non-serverless application serves concurrent users but only opens a single connection against the database, you and your users will quickly notice rising response times under load. This is because all database interactions performed in response to user requests are in contention for that single database connection. Instead of opening a single connection using a Client, use a Pool.
import { Pool } from '@neondatabase/serverless'
export const pool = new Pool({
connectionString: process.env.DATABASE_URL,
// Open up to 25 concurrent connections to the database. If more than
// 25 queries are attempted, they will be queued transparently
max: 25,
// Remove connections from the pool if they haven't been used
// to perform a query in the past minute
idleTimeoutMillis: 60 * 1000,
})The pool enables concurrent queries with reusable persistent connections. It doesn’t reduce the number of round trips, but it does increase concurrency and reduce contention for database connections.
Our prior blog post, which explored client-side connection pooling in Node.js, demonstrated that connection pooling provided more than a 10x boost in throughput and a similar reduction in application response times for our sample application.
Conclusion
Placing your backend and database near one another is essential to minimize the impact of database latency on your application’s response times. In addition, you should minimize the number of round trips between your backend and database since each round trip will add at least the minimum observed latency to your application’s overall response time.
Using Neon’s Regional Latency dashboard can help you identify the best locations to deploy your backend and database and provide a clearer picture of what impact database queries will have on your API endpoint response times.
To accelerate your development process and leverage the power of Neon Serverless Postgres, sign up and try Neon for free. Stay updated by following us on Twitter/X, and join our Discord community to share your experiences and explore how we can support you in building the next generation of applications.



